ARG-V - Adaptable Realistic Benchmark Generator for Verification
Software verification is an essential and widely used approach to ensure software works as expected. Software quality teams use verification tools that automatically search for software bugs. However, there are many such tools available to verify software. To compare these tools, the verification community organizes the SV-COMP software verification competition event. It runs verifiers on sample programs called benchmarks. Benchmarks can become outdated, thus no longer representing modern software. This can lead to verifiers falsely reporting that software is bug-free. To avoid this problem, SV-COMP needs to update its benchmark programs with new programs from online repositories with lots of existing code. However, converting these programs into usable benchmarks is a slow and difficult task. The Adaptable Realistic Benchmark Generator for Verification (ARG-V) project aims to make this process faster and easier. The project's novelties are: (1) automatically finding and converting code repository programs into SV-COMP benchmarks, and (2) classifying the new benchmarks. The project's impacts are: (1) strengthening verification tools' ability to find bugs, and (2) involving the verification community in the creation and classification of benchmark programs. The project contributes to the education of undergraduate and graduate students by developing benchmarking course modules and providing professional training.
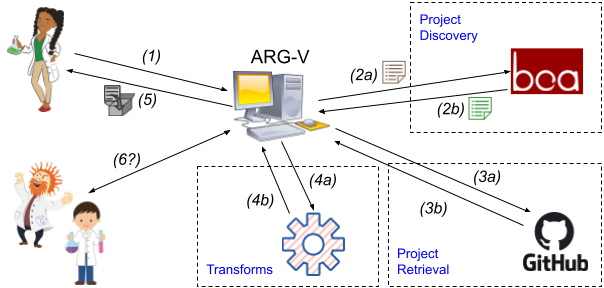
The goal of the ARG-V infrastructure is to automatically obtain a current, realistic set of benchmarks for program verifiers in the SV-COMP format. Because verifiers interpret program semantics in depth, they design different reasoning engines for specific program constructs, e.g., integer operations vs. floating-point operations. This project leverages existing infrastructure to automatically locate candidate benchmark programs from open-source repositories that contain these program constructs. The ARG-V infrastructure then applies systematic, user-defined transformations to the candidate programs to prepare them for use as benchmarks in SV-COMP. This project advances the state of the art by providing an automated solution for benchmark generation that creates realistic benchmarks from real-world programs. In addition, the project investigates the classification of the obtained benchmarks based on the specific program features and type of analysis used in verification. The built infrastructure is made available to the program verification community for use in their research, resulting in improved benchmarking and evaluation of future program verifiers.